We introduce Arboretum, the largest publicly accessible dataset designed to advance AI for biodiversity applications. This dataset,
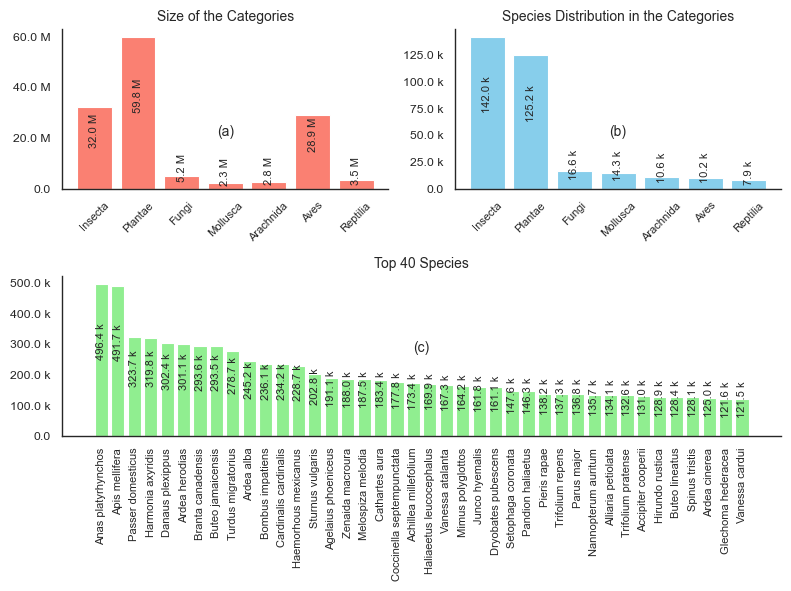
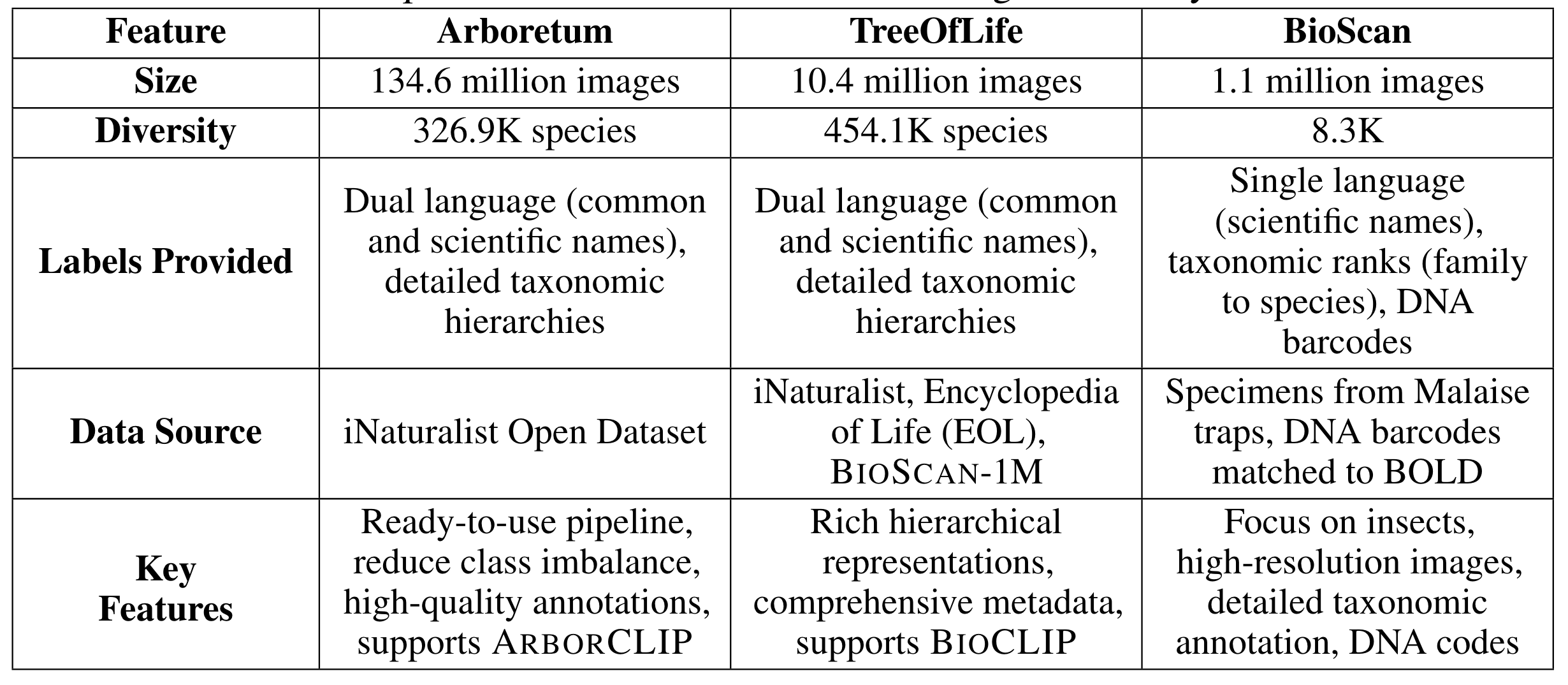
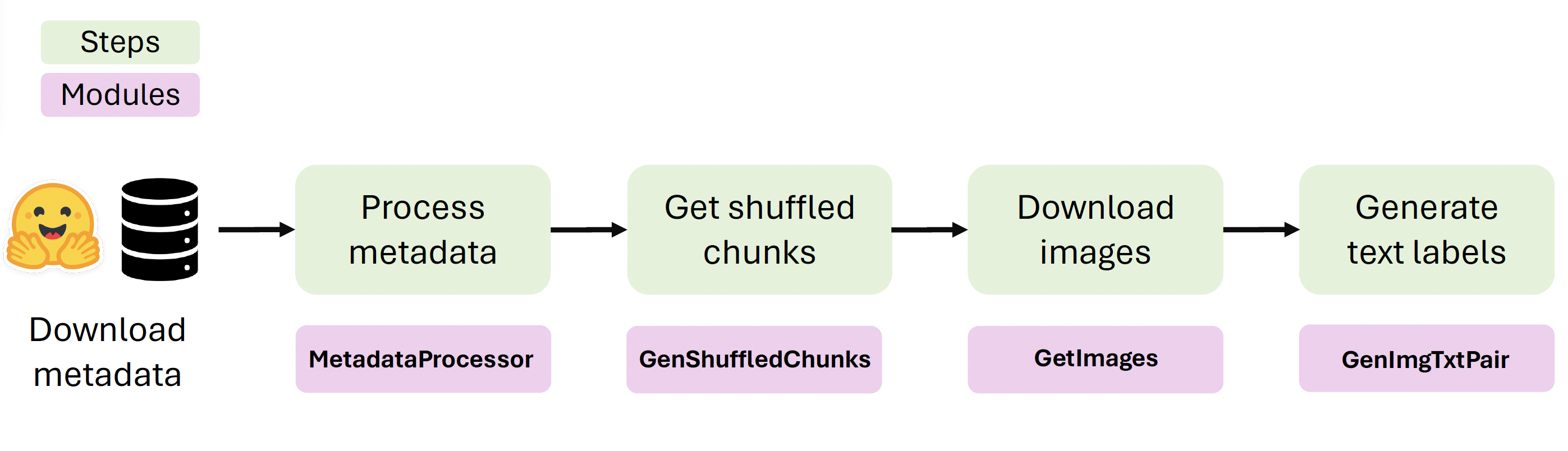
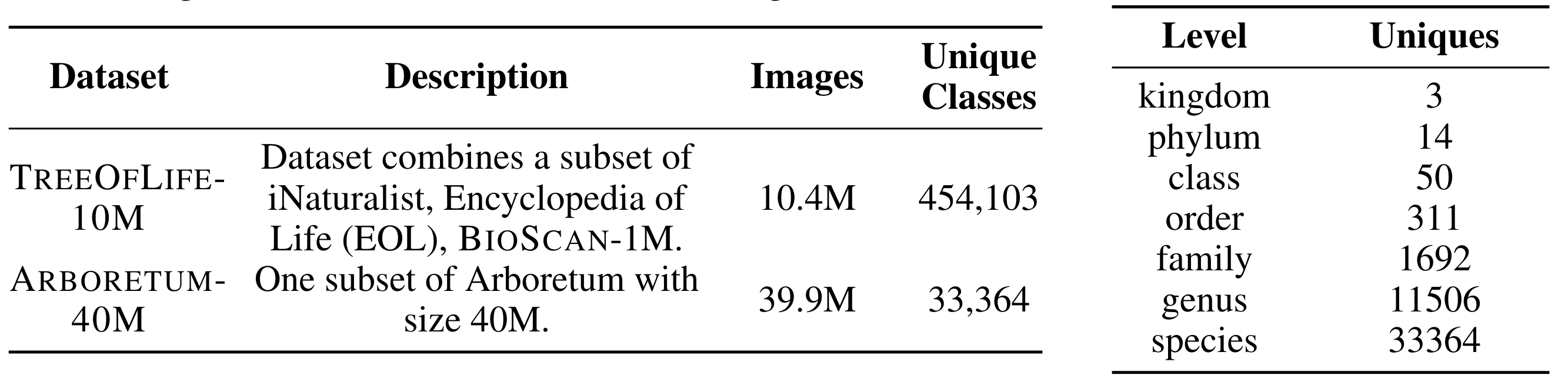
curated from the iNaturalist community science platform and vetted by domain experts to ensure accurate data, includes 134.6 million images,
surpassing existing datasets in scale by an order of magnitude. The dataset encompasses image-language paired data for a diverse set of species
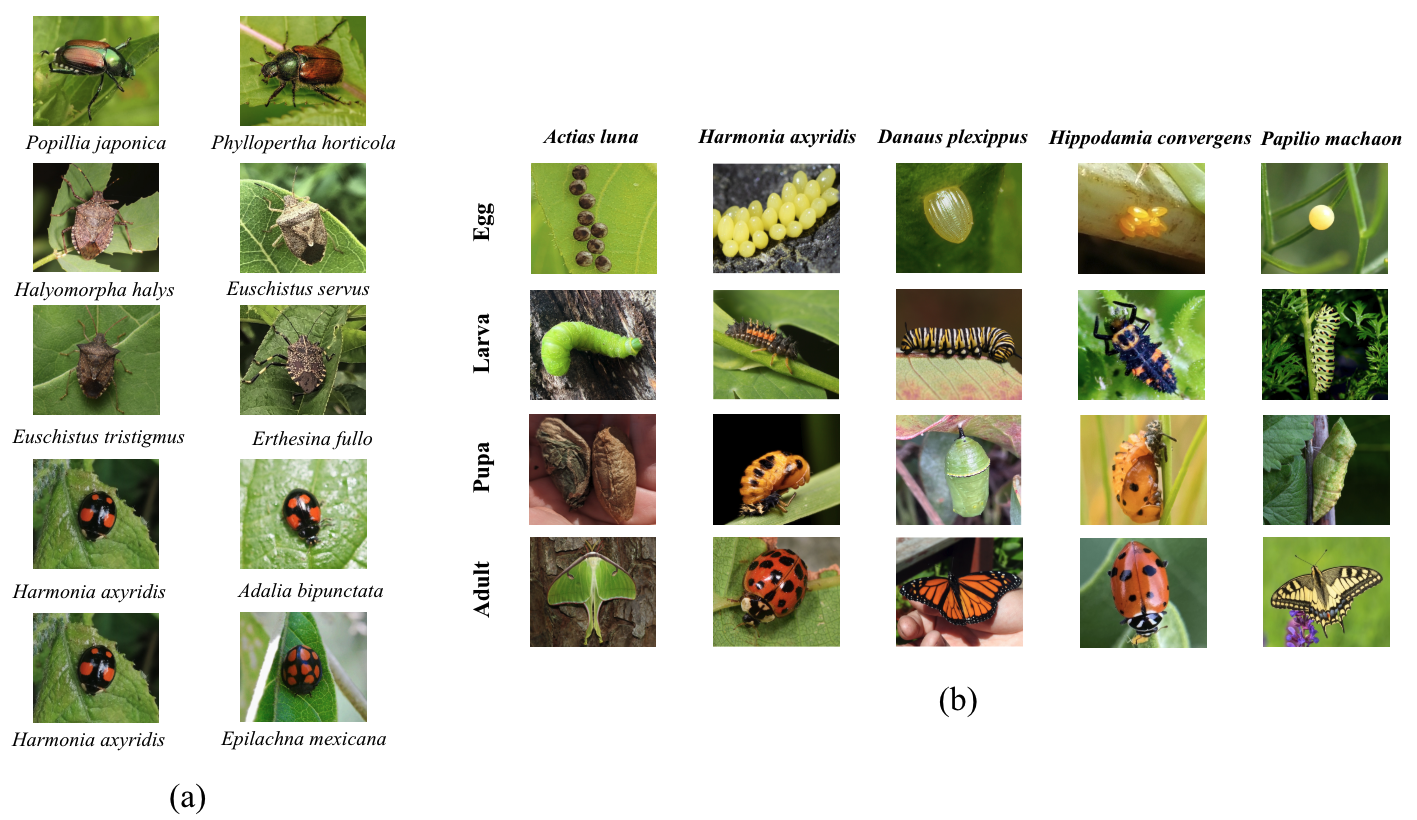
from birds (Aves), spiders/ticks/mites (Arachnida), insects (Insecta), plants (Plantae), fungus/mushrooms (Fungi), snails (Mollusca), and snakes/lizards (Reptilia),
making it a valuable resource for multimodal vision-language AI models for biodiversity assessment and agriculture research. Each image is annotated with scientific names,
taxonomic details, and common names, enhancing the robustness of AI model training. We showcase the value of Arboretum by releasing a suite of CLIP models trained using a
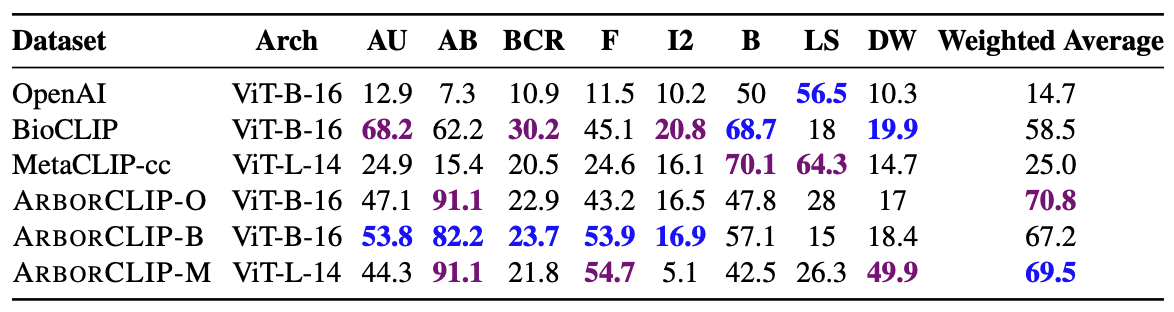
subset of 40 million captioned images. We introduce several new benchmarks for rigorous assessment, report accuracy for zero-shot learning, and evaluations across life stages,
rare species, confounding species, and various levels of the taxonomic hierarchy. We anticipate that Arboretum will spur the development of AI models that can enable a
variety of digital tools ranging from pest control strategies, crop monitoring, and worldwide biodiversity assessment and environmental conservation. These advancements are
critical for ensuring food security, preserving ecosystems, and mitigating the impacts of climate change. Arboretum is publicly available, easily accessible, and ready for immediate use.